The Language Server Index Format (LSIF)
February 19, 2019 by Dirk Bäumer
Rich code navigation without checkout
As a developer, you spend a lot of your time reading and reviewing code and not necessarily authoring new source code. For example, you may want to browse an existing codebase in a repository like GitHub or you may want to review a colleague's Pull Request.
Typically you would check out a branch or clone a repository pulling down the source code onto your local machine, open your preferred development tool, and then finally you can read and navigate the code. Wouldn't it be cool if you could do this without first cloning the repo? Imagine getting intelligent code features like hover information, Go to Definition, and Find All References without having to download source code. The blog post, First look at a rich code navigation experience, illustrates this scenario for a Pull Request review.
The goal of the Language Server Index Format (LSIF, pronounced like "else if") is to support rich code navigation in development tools or a Web UI without needing a local copy of the source code. The format is similar in spirit to the Language Server Protocol (LSP), which simplifies the integration of rich code editing capabilities into a development tool.
Why not simply use an existing LSP language server? The LSP provides rich code authoring features like auto complete, format on type, and rich code navigation. To provide these features efficiently, a language server requires all source code files be available on a local disk. LSP language servers may also read parts or all of the files into memory and compute abstract syntax trees to power these features. The goal of the Language Server Index Format is to augment the LSP protocol to support rich code navigation features without these requirements. The LSIF defines a standard format for language servers or other programming tools to emit their knowledge about a code workspace. This persisted information can later be used to answer LSP requests for the same workspace without running a language server.
Language Server Index Format
LSIF builds on LSP and it uses the same data types as defined in LSP. At a high level, LSIF models the data returned from language server requests. Same as LSP, LSIF doesn't contain any program symbol information nor does the LSIF define any symbol semantics (for example, what makes the definition of a symbol or whether a method overrides another method). The LSIF therefore doesn't define a symbol database, which is consistent with the LSP approach.
Using the existing LSP data types as the base for LSIF has another advantage as LSIF can easily be integrated into tools or servers which already understand LSP.
Let's have a look at an example. We start with a simple Typescript file named sample.ts with the content below:
function bar(): void {}
Hovering over bar() shows the following hover information in Visual Studio Code:
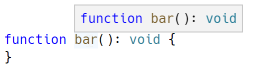
This hover information is expressed in LSP using the Hover type:
export interface Hover {
/**
* The hover's content
*/
contents: MarkupContent | MarkedString | MarkedString[];
/**
* An optional range
*/
range?: Range;
}
In the above example, the concrete value is:
{
contents: [{ language: 'typescript', value: 'function bar(): void' }];
}
A client tool would retrieve the hover content from a language server by sending a textDocument/hover request for document file:///Users/username/sample.ts at position {line: 0, character: 10}.
LSIF defines a format that language servers or standalone tools emit to describe that the tuple ['textDocument/hover', 'file:///Users/username/sample.ts', {line: 0, character: 10}] resolves to the above hover. The data can then be taken and persisted into a database.
LSP requests are position based, however results often only vary for ranges and not for single positions. In the above hover example, the hover value is the same for all positions of the identifier bar. This means the same hover value is returned when a user hovers over b in bar or over r in bar. To make the emitted data more compact, the LSIF uses ranges instead of positions. For this example, an LSIF tool emits the tuple ['textDocument/hover', 'file:///Users/username/sample.ts', { start: { line: 0, character: 9 }, end: { line: 0, character: 12 }] which includes range information.
LSIF uses graphs to emit this information. In the graph, an LSP request is represented using an edge. Documents, ranges, or request results (for example, the hover) are represented using vertices. This format has the following benefits:
- For a given code range, there can be different results. For a given identifier range, a user is interested in the hover value, the location of the definition, or to Find All References. LSIF therefore links these results with the range.
- Extending the format with additional request types or results can easily be done by adding new edge or vertex kinds.
- It is possible to emit data as soon as it is available. This enables streaming rather than having to store large amounts of data in memory. For example, emitting data for a document should be done for each file as the parsing progresses.
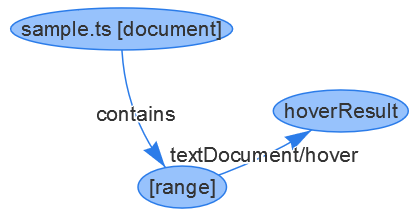
For the hover example, the emitted LSIF graph data looks as follows:
// a vertex representing the document
{ id: 1, type: "vertex", label: "document", uri: "file:///Users/username/sample.ts", languageId: "typescript" }
// a vertex representing the range for the identifier bar
{ id: 4, type: "vertex", label: "range", start: { line: 0, character: 9}, end: { line: 0, character: 12 } }
// an edge saying that the document with id 1 contains the range with id 4
{ id: 5, type: "edge", label: "contains", outV: 1, inV: 4}
// a vertex representing the actual hover result
{ id: 6, type: "vertex", label: "hoverResult",
result: {
contents: [
{ language: "typescript", value: "function bar(): void" }
]
}
}
// an edge linking the hover result to the range.
{ id: 7, type: "edge", label: "textDocument/hover", outV: 4, inV: 6 }
The corresponding graph looks like this:
The LSP also supports requests that only take a document as a parameter (they are not position based). Example requests that are useful for code comprehension are for a list of all document symbols or to compute all folding ranges. These requests are modeled in LSIF in the form [request, document] -> result.
Let's look at another example:
function bar(): void {
console.log('Hello World!');
}
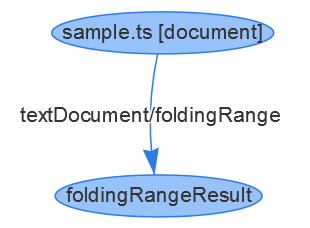
The folding range result for the document containing above function bar is emitted like this:
// a vertex representing the document
{ id: 1, type: "vertex", label: "document", uri: "file:///Users/username/sample.ts", languageId: "typescript" }
// a vertex representing the folding result
{ id: 2, type: "vertex", label: "foldingRangeResult", result: [ { startLine: 0, startCharacter: 20, endLine: 2, endCharacter: 1 } ] }
// an edge connecting the folding result to the document.
{ id: 3, type: "edge", label: "textDocument/foldingRange", outV: 1, inV: 2 }
These are only two examples of LSP requests supported by the LSIF. The current version of the LSIF specification also supports document symbols, document links, Go to Definition, Go to Declaration, Go to Type Definition, Find All References, and Go to Implementation.
We need your feedback!
We have made good initial progress on the LSIF specification and we want to open the conversation to the community so you can learn what we're working on. For feedback, please comment on the issue Language Server Index Format.
How to get started
To get started with LSIF, you can have a look at the following resources:
- The LSIF specification - The document also describes some additional optimizations that have been done to keep the emitted data compact.
- LSIF Index for TypeScript - A tool that generates LSIF for TypeScript. The README provides instructions for using the tool.
- Visual Studio Code extension for LSIF - An extension for VS Code that provides language comprehension features using an LSIF JSON dump. If you implement a new LSIF generator, you can use this extension to validate it with arbitrary source code.